
 Today I'm excited to announce the public release of a new project I've been working on: Mock Twain!
Today I'm excited to announce the public release of a new project I've been working on: Mock Twain! I started the associated Twitter account about a year ago to just mess around, sending occasional Twain-inspired quotes. A month ago I came up with the idea to tweet an entire book, and immediately using Twain as a source sprang to mind!
It's a simple enough idea, mixing a new-world digital medium with old-world art/content. Implementing it was also remarkably easy... and thus TwainBot was born! You can follow Mock Twain via Twitter (below) or check out the project's blog (new link on this site, to the right of my [ Press ] link)
Here is the executive summary:
- TwainBot will tweet the entire text of The Adventures of Tom Sawyer
- The "bot" (running on a RaspberryPi inside a hollowed out Mark Twain book) sends about 10 tweets a day, via python/tweepy
- It will take about a year to tweet the entire book

Moar Details!
I'm using Python as the "glue" for this whole project. The text (squarely in the Public Domain) comes from Project Gutenberg.
Once I removed the Project Gutenberg header/footer, as well as the Table of Contents from the file (they would make for some really boring tweets, after all) I wanted to further compress the text where possible. There were some easy substitutions I could make to save space (e.g. "--" to "-"), but I decided to not translate the entire text to 1773speak because I find it annoying. Here's a nearly complete list of substitutions I made:
- All written numbers to numeric characters (e.g. "one" to "1", "fifteen" to "15", "hundred's" to "100s", "twenty dollars" to "$20", and so on)
- "and" to "&" (this alone saved over 6000 characters, or about 45 tweets)
- "you" to "U"
- "be" to "B"
- Removed the apostrophes from "can't", "don't", "ain't"
- "with" to "w/", "without" to "w/o"
From a total of 387,560 characters to 374,802, about 3.3% compression. In other words, with only 5 minutes of work and a handful of substitutions I shaved off 91 tweets from the project. I was surprised this compression wasn't larger, but I was not aggressive or clever (e.g. "anyone" to "NE1").
Aside: If it doesn't exist already, somebody should create a packaged called "bybbreviate" or similar that implements progressively harsher and harsher phonetic substitutions to get the maximum text compression that maintains readability... human testing of readability for this idea would also be amusing, like a game of telephone.
It was important for me to preserve the readability of the text, hoping that people might actually want to follow along, and so I opted to not make a few obvious other substitutions (e.g. "to/too" to "2", which causes confusions with numbers). After the compression, I would naïvely have about 2,700 tweets if I used a running 140character window through the text. Given all the dialog, this would quickly degenerate and become hard to follow as a reader (tweets ending mid-word would be a nightmare!) Thus I needed to break the text in to more logical units: sentences!
Aside: TwainBot may be the genesis of the words laziest book club... maybe the start of a new trend? I also think ShakespeareBot would be amazing, especially if each character had an account, and each line of dialog was "acted out" on Twitter in real time, being retweeted by a central narrator account. We could bring the Bard to a whole new generation! If somebody wants to put up the cash for me to implement this, LMK....
Aside: TwainBot may be the genesis of the words laziest book club... maybe the start of a new trend? I also think ShakespeareBot would be amazing, especially if each character had an account, and each line of dialog was "acted out" on Twitter in real time, being retweeted by a central narrator account. We could bring the Bard to a whole new generation! If somebody wants to put up the cash for me to implement this, LMK....
Python's NLTK comes with a great sentence tokenizer (à la Punkt) that did a good job of parsing the text into sentences, taking in to account dialog, questions, exclamations, etc. According to this method, there are 4,856 sentences in Tom Sawyer. However, many of these sentences (about 700 in fact) are longer than 140 characters. Here's a cool histogram of the sentence lengths:
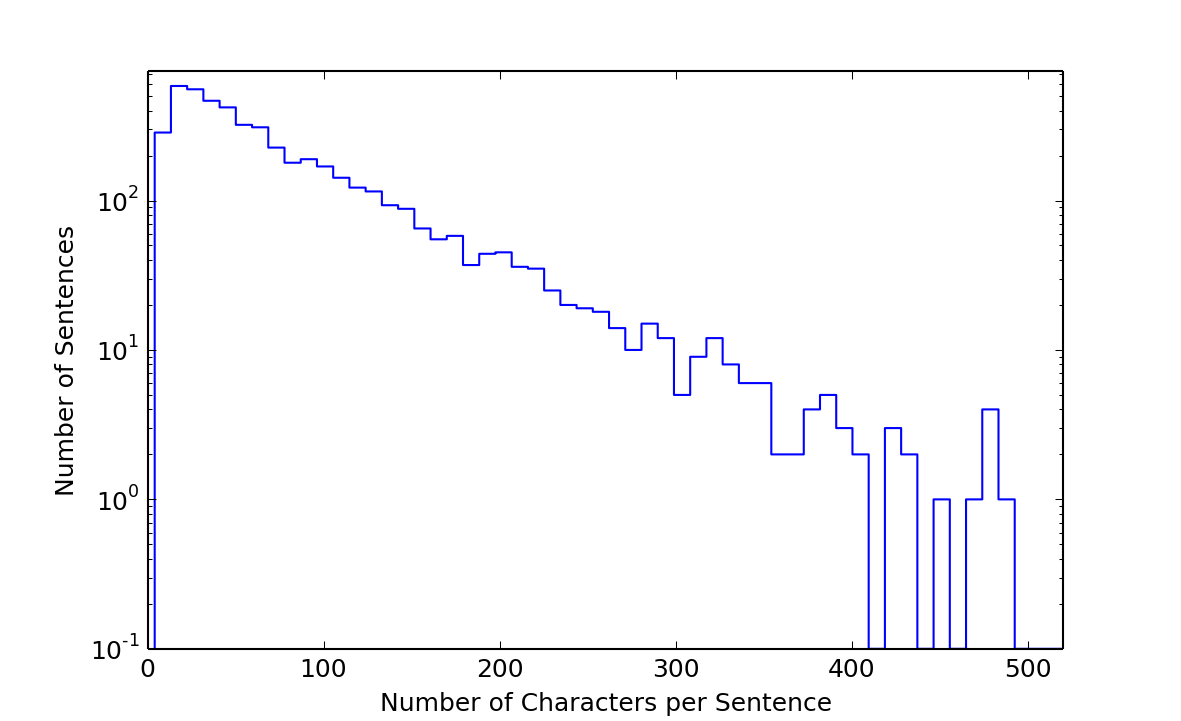
That's a sweet exponential function. The average length of a sentence in Tom Sawyer is 77 characters, the median is 53.
For the 700 sentences longer than the Twitter 140char limit I split them in to roughly even length sub-tweets, and ensuring that whole words were not broken. Since this again increased the number of tweets, I also combined tweets for sentences shorter than 140char. Given all the dialog this produced a huge savings in tweets.
In the end I arrived at 3709 tweets (saved in a pickle file), just about perfect to post 10 per day for a year.
I'll cross-post more updates about the project in the coming months, including a future github link to the code to serve as a Twitter-Bot example for others. In the meanwhile, sit back and start reading!
I'll cross-post more updates about the project in the coming months, including a future github link to the code to serve as a Twitter-Bot example for others. In the meanwhile, sit back and start reading!
Follow @Mock_Twain

No comments:
Post a Comment
Inappropriate comments, advertisements, or spam will be removed.
Posts older than 2 weeks have moderated comments.
(Anonymous commenting disabled due to increasing spam)